Workshop for Love's Labour's Lost, June 2017
Note that my previously-nifty 10-minute Shakespeare play to network graph hack now no longer works due to the Google Fusion Tables 2019 turn-down. Pour out a glass of mead for Google Fusion Tables.
This site is for the actors of the Shakespeare in the Summer troupe, and it's intended to help make the methods and decisions behind the different types of analysis more transparent, and to give you opportunities to play around more with these techniques, and make them your own, if you like.
Download the Actor Information Packets.
Table of Contents
Activity 1: Words
Activity 2: Networks
Activity 3: Feelings
WordLab Workshop at UPenn/Raw Text and Data Files
Further Reading, and Thanks
Download the Actor Information Packets.
Table of Contents
Activity 1: Words
Activity 2: Networks
Activity 3: Feelings
WordLab Workshop at UPenn/Raw Text and Data Files
Further Reading, and Thanks
Pretty much all types of textual analysis start with counting words. For the first activity, I used Voyant Tools, an open-source, web-based tool for analysis and visualization of digital texts. It's one of the foundational tools which is often used to introduce textual analysis in academic settings.
The bigger the word is, the more times it appears.
The interactive, below, is set up to let you look closely at our text. (Adjust the "scale" at the bottom left corner to see your own character's top words.) If you want to look at a different text, go to voyant-tools.org. You can copy-and-paste text right in, or, if you want to look at a bunch of texts together, the way we did here, make them into a zip file.
The bigger the word is, the more times it appears.
The interactive, below, is set up to let you look closely at our text. (Adjust the "scale" at the bottom left corner to see your own character's top words.) If you want to look at a different text, go to voyant-tools.org. You can copy-and-paste text right in, or, if you want to look at a bunch of texts together, the way we did here, make them into a zip file.
Seeing just a screen to load, or want to see more info? Check out the Voyant Page for our play.
|
A note on stopwords
A stopword list is a list of the the/and/it/is-type words that dominate our language. When they're in the textual analysis, they can make it hard to see anything else, so Voyant removes them by default. (Though because Voyant isn't designed specifically for Shakespeare, it doesn't catch them all--anyone notice "doth" in our word cloud?) Stopwords can be confusing, but also really interesting. Did you know that over 20% of the play's uses of "I" are from Biron? |

|
Imagine actors in a giant circle, and every time you say a line to someone, you step closer to them. Ultimately, you'd move closer to the people you have more interaction with, and other actors would drift to other sides of the room. That's approximately what a network graph represents. They're used a lot to analyze things like Twitter networks and to see how communities are connected (for example, check out this visualization showing two distinct communities based on political party).
Every dot is a character, and every line is a time the character speaks following another. (Note that I haven't made any attempt here to determine whether characters are actually speaking to each other--they just have lines next to each other.) Play around with it, and see what the data looks like.
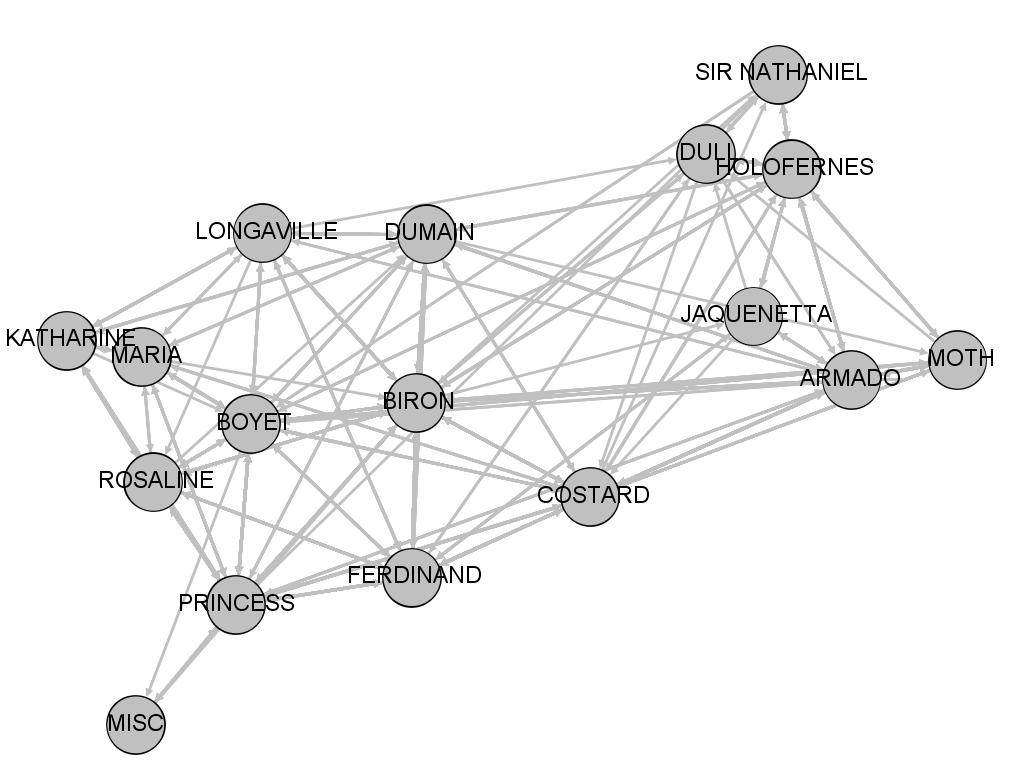 Love's Labour's Lost
Love's Labour's Lost
For the workshop, I used Gephi, which is a free open-source software program for network analysis. It does the same thing as Fusion tables, but it's got some functionality built in to do more analysis of the network and push the characters closer or further away based on the strength of the connections.
It doesn't live online so I can't post a live visualization here, but here's the image file of one way the network looks.
Keep in mind that this isn't cut-and-dried--the network will look different depending on the parameters you set. But you'll see that it's very similar to the more basic one in the Fusion tables, just a little more exaggerated.
It doesn't live online so I can't post a live visualization here, but here's the image file of one way the network looks.
Keep in mind that this isn't cut-and-dried--the network will look different depending on the parameters you set. But you'll see that it's very similar to the more basic one in the Fusion tables, just a little more exaggerated.
For contrast, here are some network graphs I made of our previous shows. Do you see anything that surprises you?
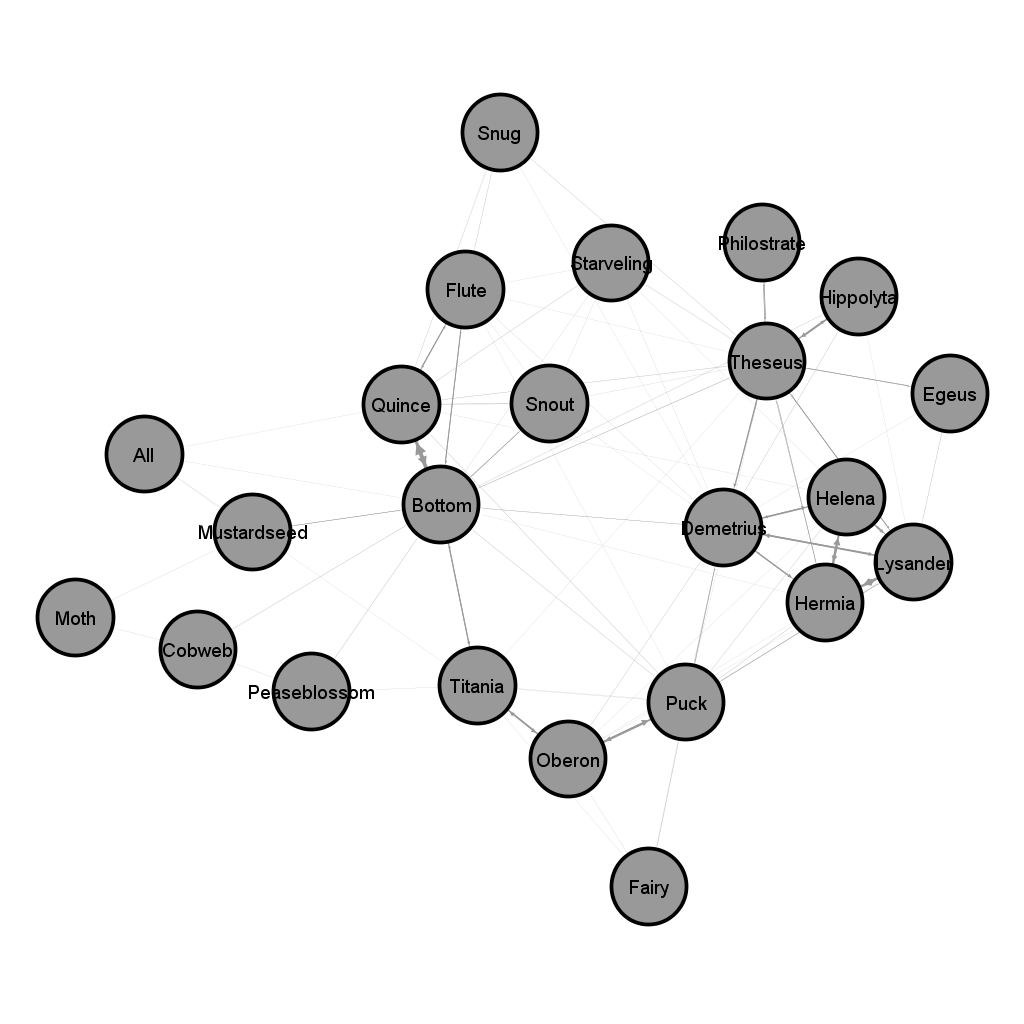
A Midsummer Night's Dream
|
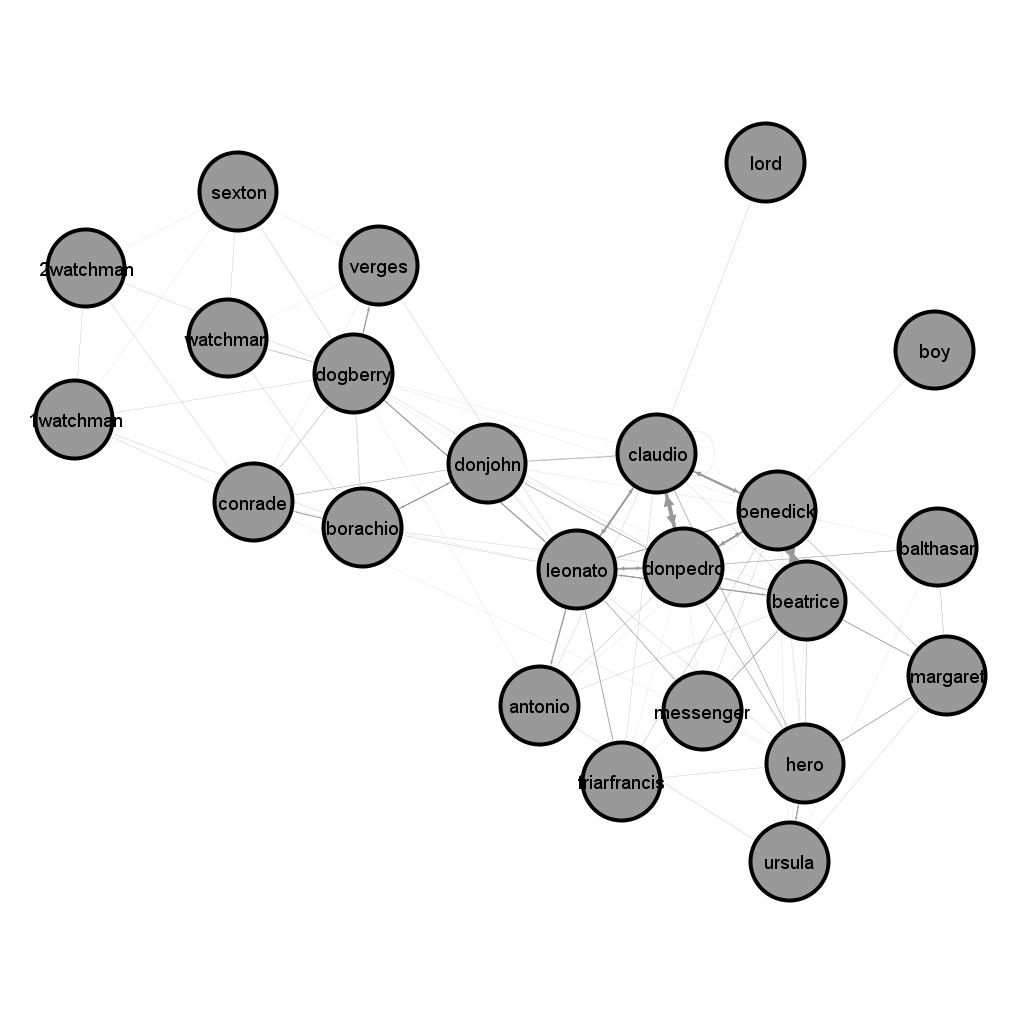
Much Ado About Nothing
|
This analysis is based on a method called "sentiment analysis." You know how social media sometimes targets ads at you based on your interest? They're using a form of sentiment analysis--if you say you really like Shakespeare, it might pick up the words "like" and "Shakespeare" and pop some theater ads into your newsfeed.
For this project, I did the analysis with a software called LIWC. I cheated a bit with this one by using a proprietary software--there are free open-source ones, but they tend not to let you dive as deeply into the specifics of a speech.
The software compares each word to a human-created dictionary of words in particular categories. English words are complicated and nuanced, so this won't give you 100% accuracy in any case. Plus, the dictionaries are designed for modern English. Still, it can give you some interesting jumping-off points for analysis.
Fun "Facts"* From Sentiment Analysis (read on to see why these aren't facts at all)
*Why these aren't really facts: Here's the full report for our play. (Explanations for the categories are at the end of the LIWC Operator's Manual). This is not very accurate--it shows what percentage of that file matches a particular category, and because the files have very different wordcounts, the numbers get quite skewed. Also, because the dictionaries are proprietary, it's hard to get under the hood and see why things might have turned out the way they did. But it's kind of fun to look through.
See the full report on your character's speech here:
For this project, I did the analysis with a software called LIWC. I cheated a bit with this one by using a proprietary software--there are free open-source ones, but they tend not to let you dive as deeply into the specifics of a speech.
The software compares each word to a human-created dictionary of words in particular categories. English words are complicated and nuanced, so this won't give you 100% accuracy in any case. Plus, the dictionaries are designed for modern English. Still, it can give you some interesting jumping-off points for analysis.
Fun "Facts"* From Sentiment Analysis (read on to see why these aren't facts at all)
- Armado uses the highest percentage of words associated with digestion.
- Biron has the highest percentage of “seeing” words.
- Boyet uses the highest percentage of body-part words.
- Costard uses the highest percentage of words associated with money.
- Dull has the highest percentage of words associated with discrepancy (would/should/could), and also with certainty (every, all, entirely).
- Dumain uses the highest percentage of sexually-associated words.
- Ferdinand has the highest percentage of interrogative words (i.e., questions).
- Holofernes uses the highest percentage of words of six letters or over.
- Jaquenetta has 0% words associated with seeing, but the play’s highest percentage of words associated with hearing.
- Katharine has 0% words associated with anxiety. Rosaline and Maria also have 0%!
- Longaville scores as the most authentic in tone, and has the most words associated with risk, and has the highest percentage of words associated with anxiety.
- Maria uses the highest percentage of words associated with feeling.
- Moth has the highest percentage of tentative words.
- Nathaniel uses the highest percentage of words associated with “insight,” i.e., cognitive processes.
- Rosaline scores the least analytic in tone (i.e., more informal, personal, narrative)
*Why these aren't really facts: Here's the full report for our play. (Explanations for the categories are at the end of the LIWC Operator's Manual). This is not very accurate--it shows what percentage of that file matches a particular category, and because the files have very different wordcounts, the numbers get quite skewed. Also, because the dictionaries are proprietary, it's hard to get under the hood and see why things might have turned out the way they did. But it's kind of fun to look through.
See the full report on your character's speech here:
- Armado speech and analysis
- Biron speech and analysis
- Boyet speech and analysis
- Costard speech and analysis
- Dumain speech and analysis
- Ferdinand speech and analysis
- Holofernes speech and analysis
- Katharine speech and analysis
- Longaville speech and analysis
- Maria speech and analysis
- Moth speech and analysis
- Nathaniel speech and analysis
- Princess speech and analysis
- Rosaline speech and analysis
|
|
(This is some material and slides I put up for a 6/21 workshop/brainstorming session at WordLab, a textual analysis group at the University of Pennsylvania.)
Plain-text uncut versions of text are pulled from this version (the HTML tagging structure made it a little easier to manipulate). I decided to use uncut versions of the text for Activity 1 and 2 because they're making generalizations about the play and characters, which I felt might be slightly more authentic with the uncut text. I used the cut text for the more specific analysis of Activity 3. |
People love to find new ways of interacting with Shakespeare, which probably is one reason why there are so many computer-assisted analyses of Shakespeare's plays. Some focus on authorship analysis, attempting to show that Shakespeare had help writing the Henry VI plays, or that he might have written another play no one thought he did, or that Shakespeare's plays were probably not written by Oxford. Others focus on data analysis, forming Shakespeare's tragedies into network graphs and designing the plays into visual art.
I owe about a billion thanks to:
I owe about a billion thanks to:
- Friends and scholars who helped me brainstorm ideas: Jody Griffith, Daniel Ruppel, Jenny Spohrer, and Michael Strupczewski
- WordLab at the University of Pennsylvania (particularly Scott Enderle) for all of their fantastic ideas and suggestions
- And most importantly, the Summer Shakespeare Theatre Troup (particularly Bridget Reilly Beauchamp, Benjamin Lloyd, Ali Roy, Pulley and Buttonhole Theatre Company, and White Pines Productions)